title: Network analysis: Graph visualization for discovery and exploration of connections & relations authors: - Markus Mandalka
Network analysis: Graph visualization for discovery and exploration of connections & relations
Visualization of relations and connections between entities like persons or organizations within and across documents (co-occurrences of named entities)
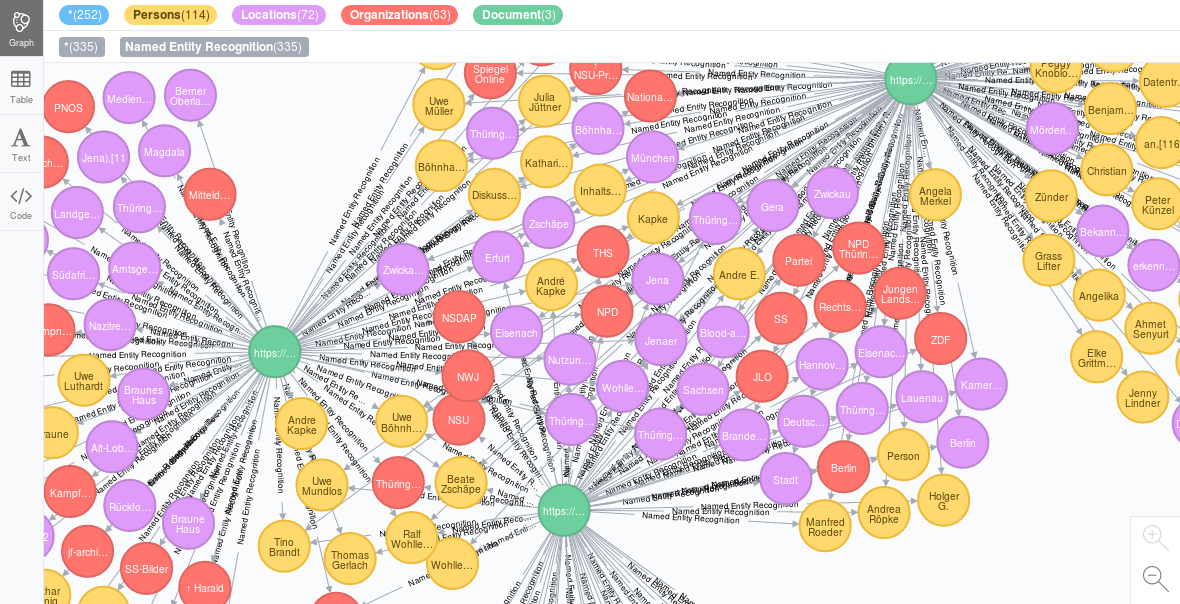
The graph/network analysis view shows you the direct and indirect relations, connections and networks between named entities like persons, organizations or main concepts which occur together (co-occurences) in your content, datasources and documents or are connected in your Linked Data Knowledge Graph.
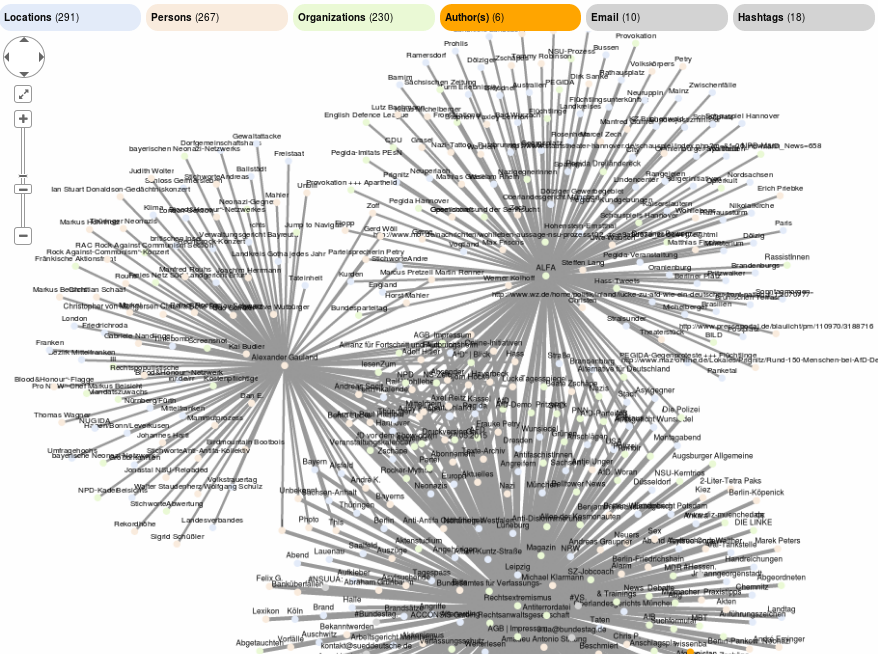
Color map and statistics of entity types/classes
The statistics and color map in the bar shows you how many entities of each class are loaded to the graph visualization and which colors they have in the graph visualization.
Size of entities/nodes: How many documents contain the entity
The size of the entity circle / node visualizes how many documents contain this entity.
Size of connections / edges: Co-occurences of connected entities in documents
The edge / connection width is visualizing in how many documents both connected entities occur together.
Extend: Load more entities & connections
The graph shows you some first entities, which are extracted from documents matching your search query or connected to the entity you started to search for/from.
On this base you can extend the graph by additional connections and entities:
By a click on a entity or node more connections from / to this entity from / to other named entities (maybe yet not in the graph visualization) are loaded.
Document based graph exploration by augmentation of connections with documents
A click on a connection / edge with the connection type / property "Documents (co-occurence)" shows you in how many and which documents the connected entities occur together.
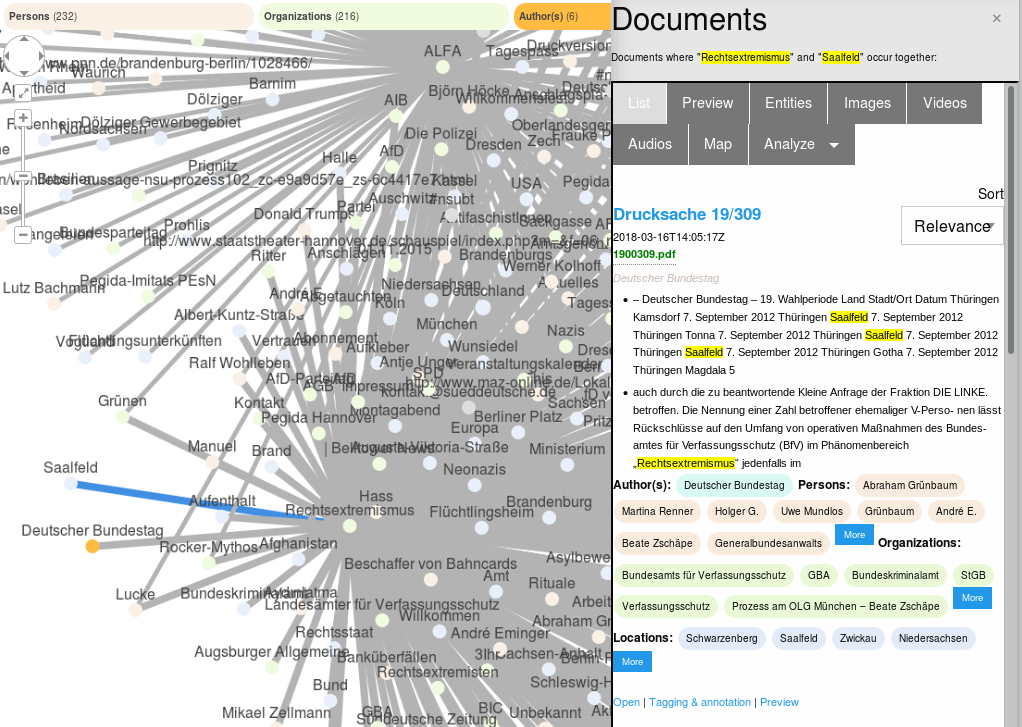
In the tab "List" you see a list of documents in which both connected entities occur.
In the tab "Preview" you can preview the full text and metadata of a single document.
In the tab "Entities" you get an aggregated overview of other named entities within this documents or by other options in the sub menu "Analyze" you can analyze or filter this documents .
Graph visualization and graph analysis by full-text search
You can start a graph visualization from full text search (not only for entities, but for keywords in your documents, too) in the search user interface.
Therefore do a full text search and click on the view "Connections (Graph)" in tab/menu analysis.
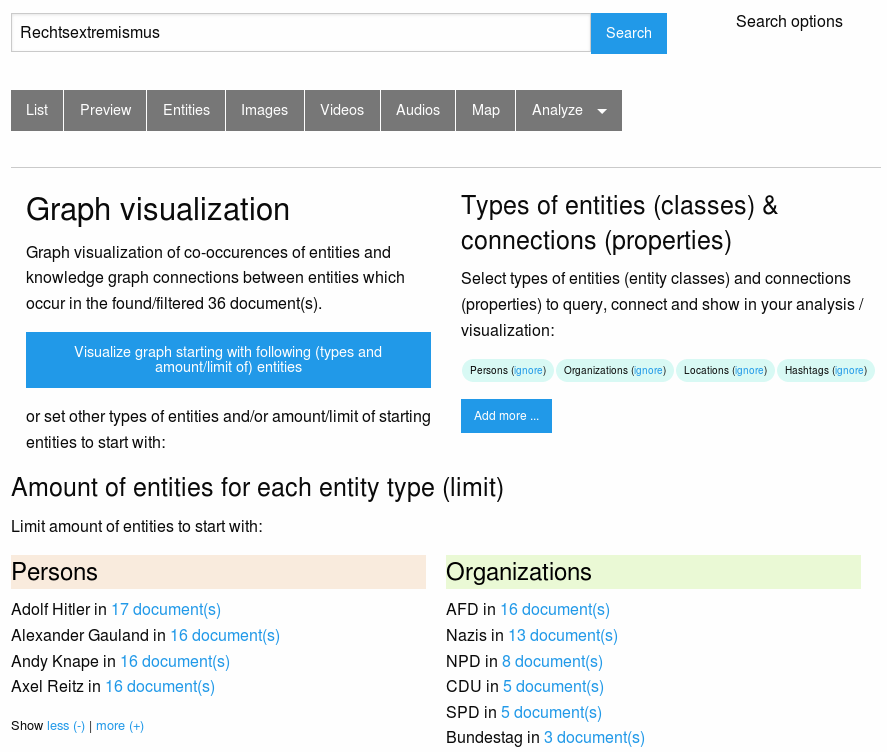
There you can set which types (classes) of entities and connections (properties) to use for graph analysis and graph visualization and with how many of each entities to start with.
By click on the button "Visualize graph" you open the graph explorer and can extend the graph by clicking an entity / node.
Thesaurus or Ontology based entity graph exploration by concepts (SKOS & RDF)
If you set up a thesaurus or an ontology, the linked concepts of your thesaurus or the selected ontology are shown in the graph, too, so additionally to occuring entities like people, organizations and locations you can explore by concepts from your thesaurus in the content, too.
Limitations
This is a first alpha release with some bugs and limitations.
There is not an user interface control element for setting limits how many connections should be loaded at once, which can cause problems if you enable entities from Named Entity Recognition by machine learning (since that results in many false positives) or using very generic thesauri.
In future releases there will be a sepraration of properties for Named Entitiy Recognition by Machine Learning and Named Entity Extraction by your thesaurus or tags and an user interface element for showing and setting custom limits for extending single entities / loading their connections.
Automatic extraction of named entities from documents (Named Entity Extraction)
Open Semantic Search or Open Semantic ETL extracts named entities defined in your thesaurus, ontologies or lists of names or recognized by Named Entity Recognition by machine learning automatically.
Named entities like persons, organizations or places
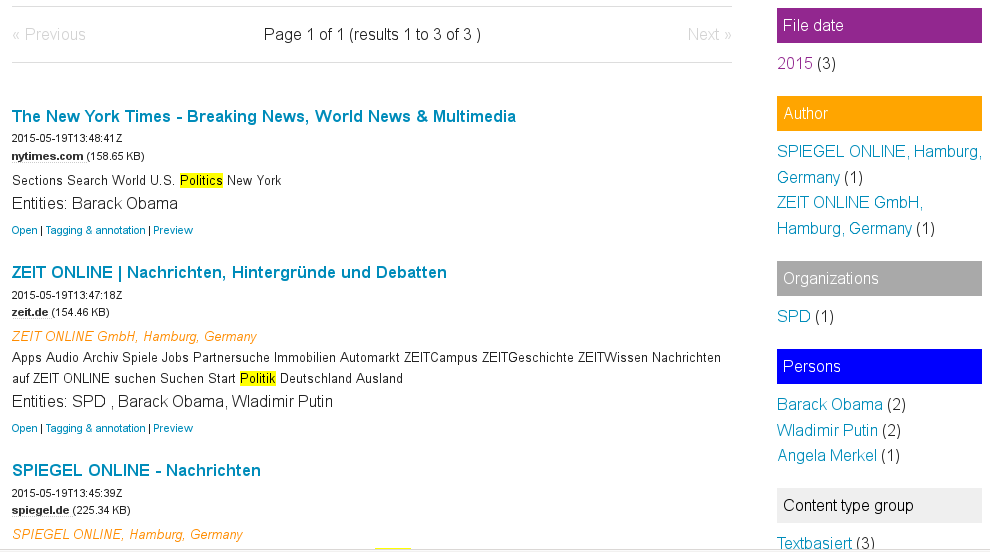
Extracted named entities like persons, organizations or locations (Named entity extraction) are used for structured navigation, aggregated overviews and interactive filters (faceted search) and to be able to get leads for connections and networks because you can analyze which persons, organizations or places occor together in how many documents.
Automatic Named Entity Recognition by machine learning (ML) for automatic classification and annotation of text parts
Additionally to known named entities in a thesaurus or imported ontologies other data analysis plugins integrate Named Entity Recognition (NER) by spaCy and/or Stanford Named Entities Recognizer (Stanford NER).
Named Entity Extraction of yet unknown entities or names
So by integration of machine learning for analysing the structure of the text and classifying parts/words of the sentences to categories like person, location or organization, many yet unknown named entities can be extracted, which aren't configured or listed yet in the thesaurus or a list of names or ontology.
Therefore it uses models trained with existing annotations of a large text corpus, so after that they can "predict" or better: guess by probability if a part of a sentence is a name of a person, a name of an organization, a verb or a place.
Find more by combination with thesaurus and ontologies
Since no machine learning algorithm and machine learning model is perfect, the search engine combines the analysis with other methods and data which is curated by human editors.
Therefore you can add important names, aliases and alternate labels to the thesaurus, so the search engine will extract them even if the named entities recognition fails.
You don't have to add each name yourself:
By the ontologies manager you can import thousands of names from Open Data like Wikidata which offers an universal structured database with names of people like for example lists of names of politicians and members of parliament(s).
Improve OCR results
Additional entities in the thesaurus are added to the OCR dictionary and so they are found better in scanned documents by the automatic OCR integration for example for images of scanned pages of legacy documents within PDF files.
Manual tagging and annotation
Since no automatic analysis and automatic tagging or annotation is perfect you can tag manually documents by the semantic tagger or annotate visual parts/words/names/paragraphs/senteces within documents by Hypothesis annotator.
Open Source tool, web app and web user interface (UI) for discovery, exploration and visualization of a graph
The integrated Open Source software Open Semantic Visual Linked Data Knowledge Graph Explorer is a web app providing user interfaces (UI) to discover, explore and visualize linked data in a graph for visualization and exploration of direct and indirect connections between entities like people, organizations and locations in your Linked Data Knowledge Graph.
Neo4J browser
Alternate you can use the Neo4j browser by Cypher graph query language:
Therefore enable the Open Source ETL plugin for integration with the Neo4j graph database in the config.